TL;DR a nova funcionalidade de URLs Iniciais permite especificar manualmente as páginas web a incluir inicialmente no seu relatório. Combine isto com as opções de Exclusões e Crawling Profundo para personalizar o comportamento do web crawler conforme as suas necessidades.

O Rocket Validator fornece a abordagem mais simples para gerar relatórios de validação de sites inteiros. Tudo o que precisa fazer é introduzir um URL de Início, normalmente a página inicial, e o nosso web crawler totalmente automatizado irá encontrar as ligações internas a partir daí e verificar cada página web usando o W3C HTML Validator e o verificador de acessibilidade Axe Core.
Embora o nosso crawler encontre automaticamente ligações internas nos seus sites seguindo-as a partir do URL de Início, há momentos em que você precisa de mais controlo sobre as páginas web exactas incluídas no relatório, por exemplo, pode querer garantir que certas páginas são incluídas, ou que alguma secção é inteiramente excluída. Vamos explorar as opções avançadas que pode usar para ter mais controlo sobre as páginas web incluídas nos seus relatórios de validação de site.
Usar um sitemap XML (ou TXT)
Como explicado em Sitemaps.org:
Os Sitemaps são uma forma fácil para os webmasters informarem os motores de busca sobre páginas nos seus sites que estão disponíveis para crawling. Na sua forma mais simples, um Sitemap é um ficheiro XML que lista URLs para um site juntamente com metadados adicionais sobre cada URL (quando foi actualizado pela última vez, com que frequência costuma mudar, e quão importante é, relativamente a outros URLs no site) para que os motores de busca possam fazer crawling do site de forma mais inteligente.
Os web crawlers normalmente descobrem páginas através de ligações dentro do site e de outros sites. Os Sitemaps complementam estes dados para permitir que crawlers que suportem Sitemaps apanhem todos os URLs no Sitemap e aprendam sobre esses URLs usando os metadados associados. Usar o protocolo Sitemap não garante que páginas web sejam incluídas em motores de busca, mas fornece dicas para web crawlers fazerem um melhor trabalho no crawling do seu site.
O Rocket Validator aceita sitemaps XML e TXT, desde que o ficheiro sitemap esteja hospedado no mesmo subdomínio que as páginas web. Usar um sitemap é frequentemente a opção mais conveniente, pois provavelmente já tem um sitemap no seu site para fins de SEO, mas há momentos em que isso não é uma opção porque não tem acesso ao servidor, ou não quer ter o esforço extra de construir um sitemap. É aí que entram as nossas opções avançadas de crawling para URLs Iniciais e Exclusões, mas vamos primeiro falar sobre Crawling Profundo.
Crawling profundo
Quando o Rocket Validator começa a gerar o seu relatório de validação de site, visita o seu URL de Início (que pode ser uma página HTML ou um sitemap XML / TXT), procura pelas páginas web internas ligadas (aquelas no mesmo subdomínio), e adiciona-as ao relatório do site.
Este processo é então repetido para cada página web adicionada ao relatório, para que o crawler encontre recursivamente novas ligações internas. É a isto que chamamos Crawling Profundo e é assim que podemos descobrir milhares de páginas web nos seus sites seguindo ligações internas.
O Crawling Profundo está activado por defeito, mas como utilizador Pro, pode desactivar este comportamento usando as opções de Crawling Avançado para casos em que quer mais controlo sobre as páginas web exactas que quer incluir no seu relatório. Consulte este post de blog para mais detalhes sobre Crawling Profundo.
URLs iniciais
A descoberta de ligações internas a partir do URL de Início é a abordagem mais simples para gerar um relatório de site, mas há momentos em que você quer especificar as páginas web exactas a serem incluídas e não pode facilmente criar um sitemap XML.
A nova opção avançada URLs Iniciais está aqui para resolver isto. Pode agora especificar a lista exacta de URLs a serem incluídos no relatório, para que o nosso crawler os adicione directamente na primeira passagem. O novo campo é uma área de texto que aceita uma lista de URLs, um por linha, onde cada URL deve ser absoluto e interno em relação ao campo URL de Início:
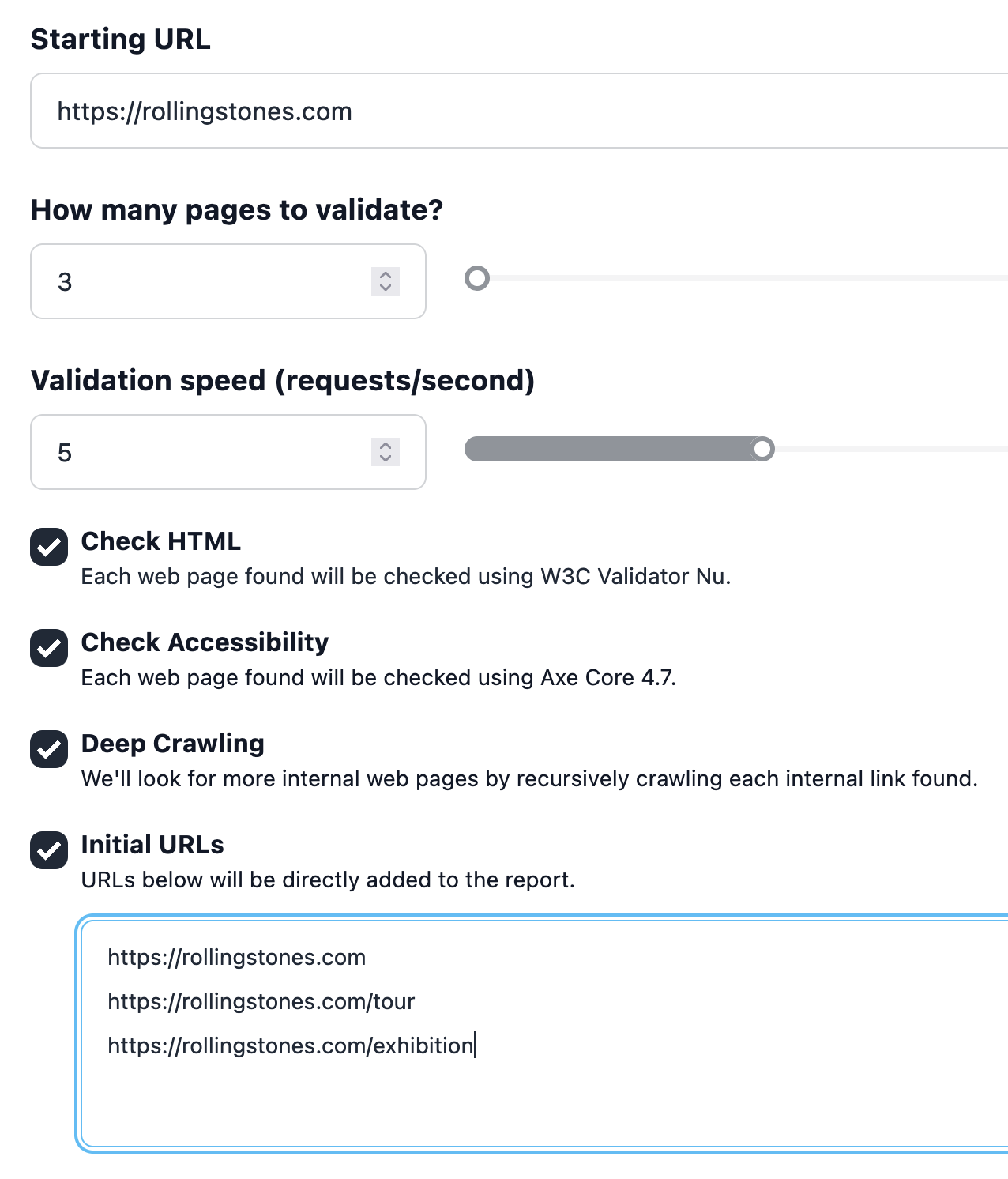
O nosso web crawler irá pegar nestes URLs iniciais e adicioná-los ao relatório do site. Depois disso, se o Crawling Profundo estiver activado, irá segui-los recursivamente para adicionar mais páginas web. Se estiver desactivado, irá parar por aí.
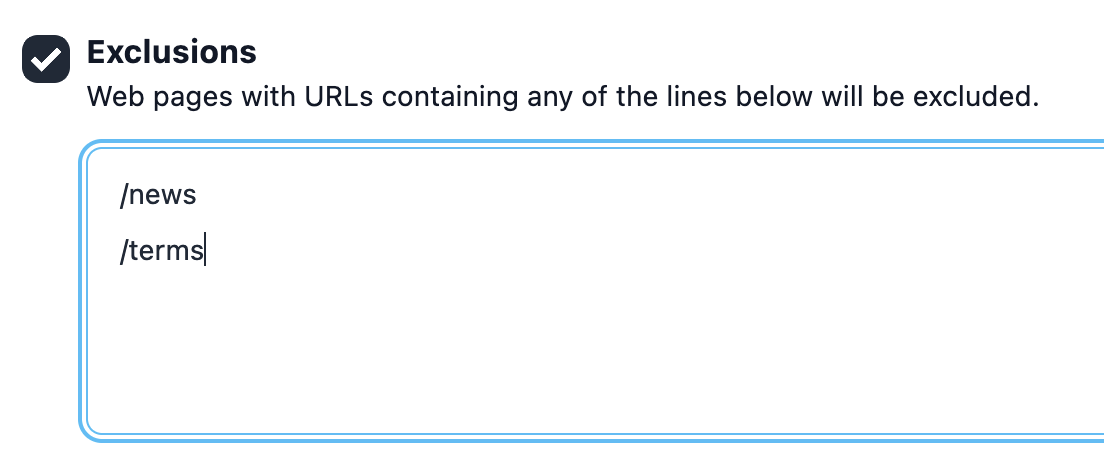
Excluir URLs
Caso queira ignorar alguns URLs ou mesmo secções inteiras do seu site, pode usar a nova funcionalidade de Exclusões. Basta introduzir alguns URLs ou caminhos, um por linha, e URLs que contenham qualquer um deles serão excluídos do seu relatório de validação de site. Mais sobre Exclusões neste post de blog.
Combinar opções avançadas de crawling
Os novos controlos de Crawling Avançado dão-lhe muita flexibilidade para definir como gostaria que o nosso web crawler se comportasse:
- Use as opções predefinidas para deixar o nosso web crawler descobrir automaticamente as páginas web internas a partir de um URL de Início.
- Introduza um sitemap XML ou TXT para definir uma lista específica de URLs a serem validados, e desactive o Crawling Profundo para validar apenas os que estão nessa lista.
- Defina URLs Iniciais quando não tem acesso a sitemaps XML, e deixe o Crawling Profundo activado para adicionar as páginas web ligadas, ou desactive-o para restringi-lo à lista inicial.
- Especifique exclusões para ignorar secções específicas do seu site.
Esperamos que as Opções Avançadas de Crawling lhe dêem um novo nível de controlo nos seus relatórios de validação de site!